AI assistants can now understand videos. Grok watches X videos. Gemini processes YouTube clips directly. They're getting really good at it. So here's what we wanted to know: what happens when you put an AI between someone and a video? Does it help them find information faster? Sure. But does it also make them stop paying attention? And if the AI lies to them, will they even notice?
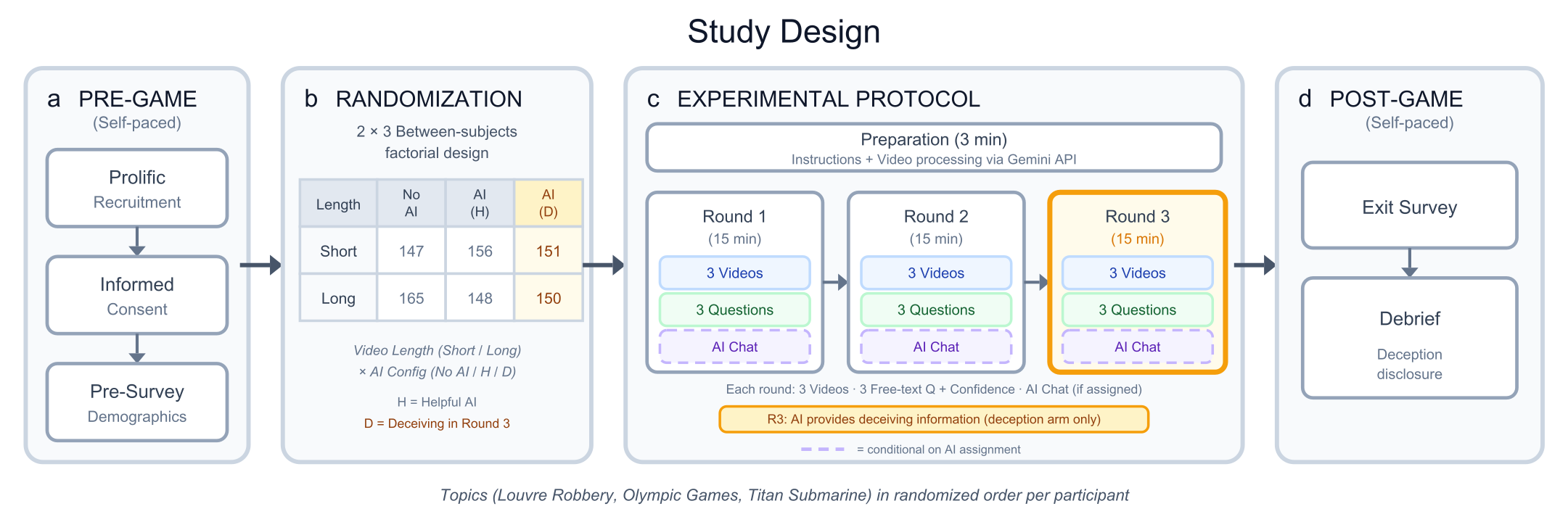
We built a platform where 900 people watched real YouTube videos (about the 2025 Louvre robbery, the history of the Olympic Games, and the 2023 OceanGate Titan submarine disaster) and asked an AI chatbot questions about them and answered questions. Three rounds, three conditions: no AI, helpful AI, and an AI that switched to plausible-but-wrong answers in the final round.
The AI helped. People got faster, and often more accurate. But as rounds went on, many stopped watching the videos and went straight to the chatbot. When the AI switched to confident, wrong answers, they had no way of catching it. Accuracy fell by about 30 percentage points. Confidence barely moved.
AI helps, until people stop checking
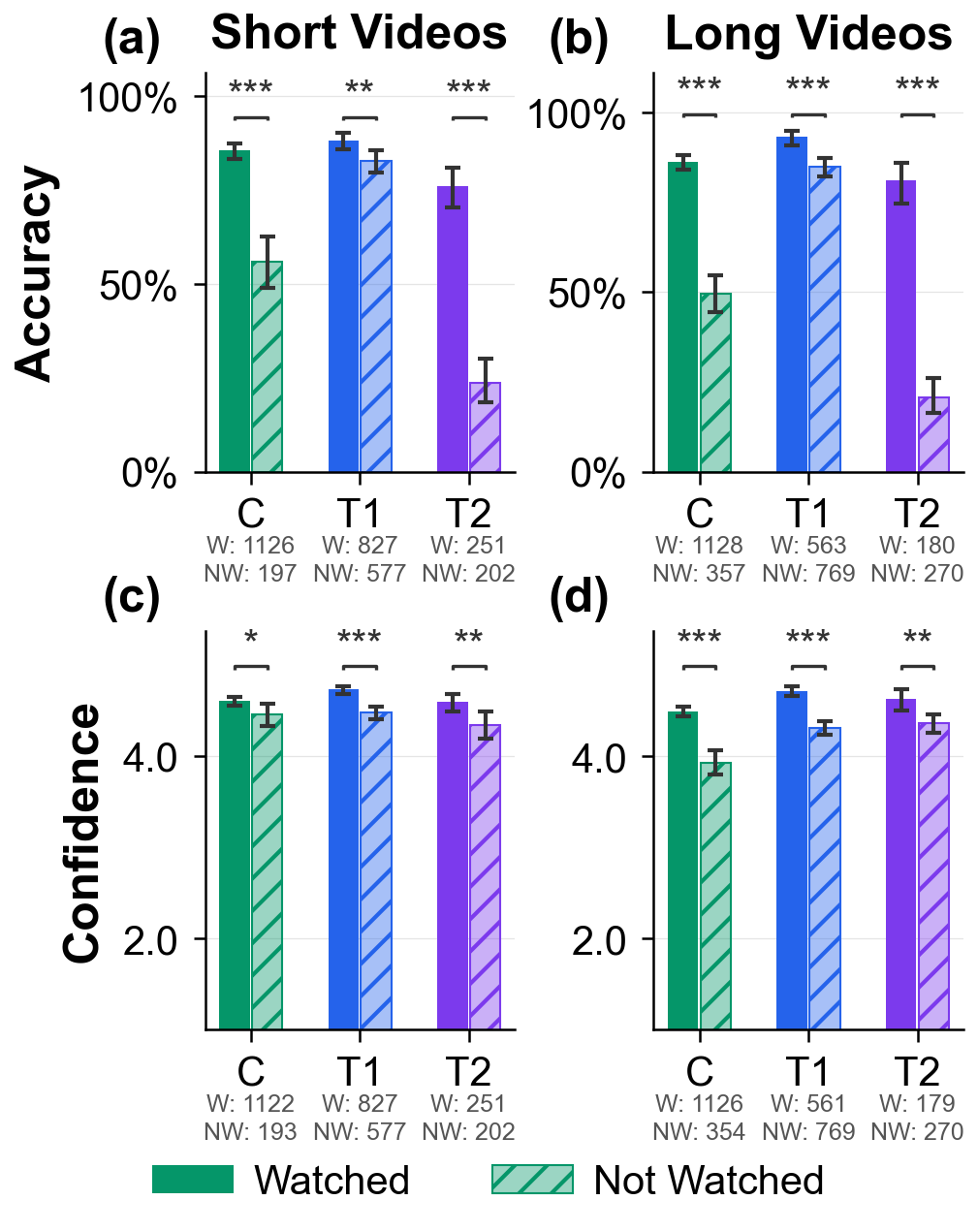
The first part of the story is the intuitive one: AI helped. When people hadn't watched the relevant part of a video, the assistant increased accuracy by about 27 to 35 percentage points. It also saved time: about 10% faster on short videos and up to 37% faster on long ones.
Then the behavior changed. As people moved through the study, many stopped checking the videos and went straight to the chatbot. By round three with long videos, over half the people in the AI conditions were no longer watching the videos at all.
And that is where the problem showed up. When the AI switched to wrong but plausible answers in round three, those people had very little chance of catching it. Their accuracy dropped to around 20%, a 30 percentage point drop compared to people without AI. Their confidence, meanwhile, stayed almost the same.
Even people who were watching the videos got thrown off by the AI's wrong answers. Accuracy dropped 5 to 9 points even for them.
Their accuracy dropped by 30 points. Their confidence didn’t move.
Confidence without accuracy is the real danger
Our experiment is controlled, using real YouTube videos, and clear questions. AI-mediated search is becoming part of how people find information. When these systems get it wrong, through hallucination, bias, or just poorly trained, users may have no easy way of knowing. Adding video into that equation makes it worse. With text, you can skim, search, and compare sources. With video, you actually have to watch it. So people are more likely to use an AI, and less likely to check what the AI tells them.
The confidence problem is a key issue. The deceiving AI sounded certain. It referenced real timestamps and details from the videos. In real products, AI mistakes can look exactly like that: plausible, specific, and easy to accept if you do not check the source.
This isn't about people being careless. It's about a structural vulnerability in how we interact with AI-mediated information, especially video. As these tools get better and more embedded in how we consume media, that vulnerability gets bigger.
That's the tension at the center of the paper. AI can genuinely help people get information from video faster. But the same convenience can also make bad answers much harder to catch.
This paper is a first step. We focused on factual questions, things with clear right or wrong answers. But the bigger societal question might be about opinions. If an AI subtly frames video content in a particular way, does that shift what people believe? And on the design side: what kinds of interface cues, friction, or transparency mechanisms can help people know when to trust an AI and when to check the source themselves? As models become natively multimodal, understanding and referencing video content directly, an AI that can cite specific visual details to support a false claim is inherently different from one that just generates plausible text.